How to analyze a huge data file with Pandas (codes included)
In previous post, we have learnt the basics of using Pandas library in Python.
We have learnt that Pandas is incredibly powerful for data analysis purpose and can do all sorts of basic analysis in a least number of lines of codes. But what if our data is huge (like over 1GB or several GBs)!
Key idea — read the file in chunks so RAM only ever holds a slice. You don’t need to load a multi-GB file all at once. pd.read_csv(..., chunksize=N) returns an iterator of DataFrames, each with N rows; you loop over it, process one chunk, and move on — so peak memory is roughly one chunk, not the whole file. That’s the difference between a job that crashes with a MemoryError and one that finishes in seconds.
Try using plain Python
The strategy for such files is not to take everything into memory at one time but read it in chunks. We can also do that using simple Python without using any library.
import pandas as pd
import os, sys, glob
import numpy as np
import enum # Enum for size units
import time
import matplotlib.pyplot as plt
from datetime import datetime as dt
class SIZE_UNIT(enum.Enum):
BYTES = 1
KB = 2
MB = 3
GB = 4
def convert_unit(size_in_bytes, unit):
""" Convert the size from bytes to other units like KB, MB or GB"""
if unit == SIZE_UNIT.KB:
return size_in_bytes/1024
elif unit == SIZE_UNIT.MB:
return size_in_bytes/(1024*1024)
elif unit == SIZE_UNIT.GB:
return size_in_bytes/(1024*1024*1024)
else:
return size_in_bytes
def get_file_size(file_name, size_type = SIZE_UNIT.BYTES ):
""" Get file in size in given unit like KB, MB or GB"""
size = os.path.getsize(file_name)
return convert_unit(size, size_type)
## Plot the data
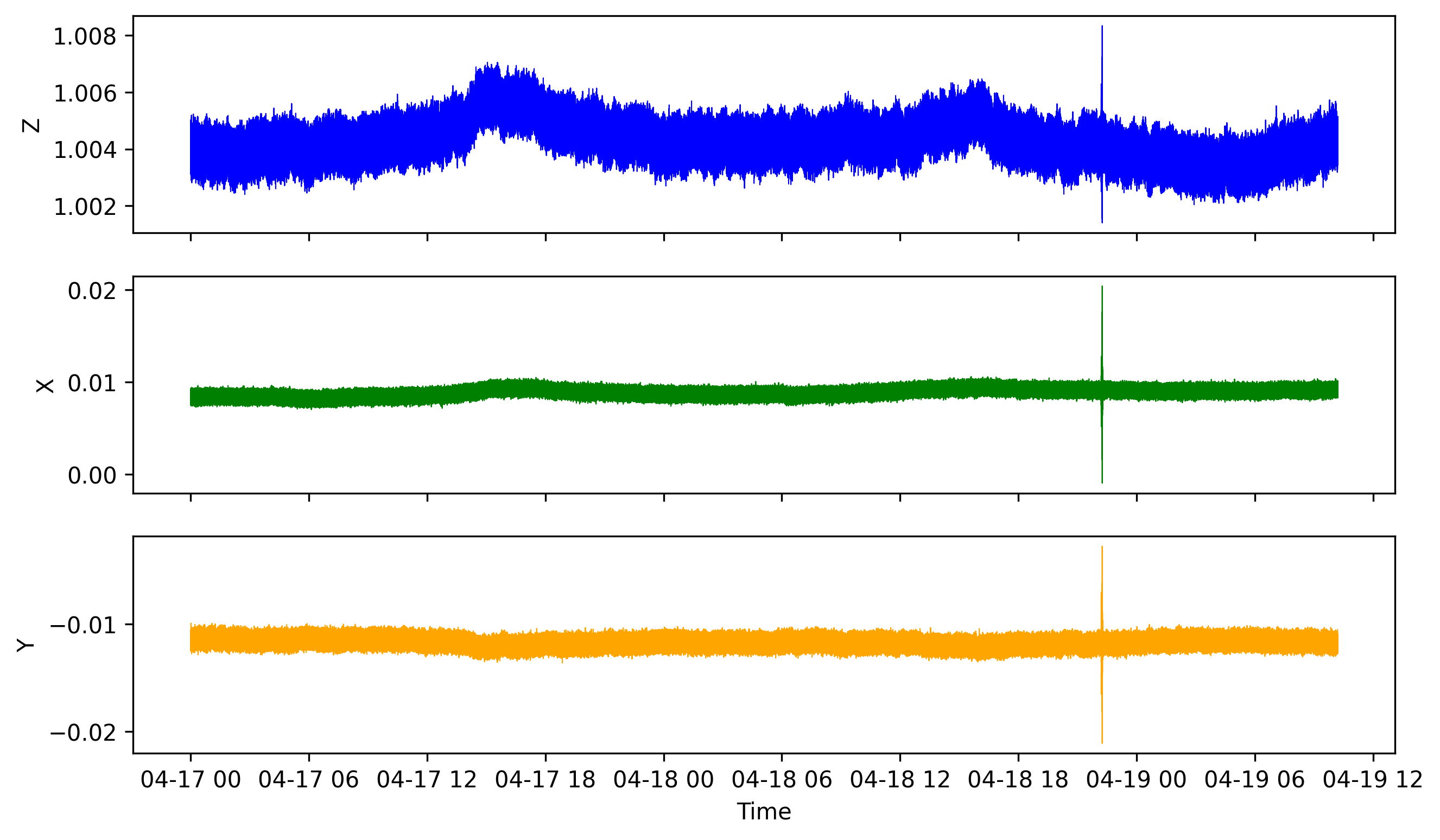
def plot_data(datetime_array, z_array, x_array, y_array, output="data_plot_ts.png"):
# Create figure and plot space
fig, ax = plt.subplots(3, 1, figsize=(10, 6), sharex=True)
# Add x-axis and y-axis
ax[0].plot(datetime_array,
z_array,
color='blue', lw=0.5)
ax[0].set_ylabel("Z")
ax[1].plot(datetime_array,
x_array,
color='green', lw=0.5)
ax[1].set_ylabel("X")
ax[2].plot(datetime_array,
y_array,
color='orange', lw=0.5)
ax[2].set_ylabel("Y")
plt.xlabel("Time")
plt.savefig(output, bbox_inches='tight', dpi=300)
plt.close('all')
datalocation = "data"
all_data = glob.glob(os.path.join(datalocation, "*.csv"))
# print(all_data)
filename = all_data[0]
# print(filename)
filesize = get_file_size(filename, SIZE_UNIT.MB)
print(f"{filename} is of size {filesize:.2f} MB")
use_plain_python = 1
if use_plain_python:
chunksize = 10**6
print("Buffer size is: ", convert_unit(chunksize, SIZE_UNIT.MB)) #depends on your RAM size
starttime = time.perf_counter()
x_array = np.array([],dtype=np.float64)
y_array = np.array([],dtype=np.float64)
z_array = np.array([],dtype=np.float64)
datetime_array = np.array([],dtype='datetime64')
with open(filename, mode= 'r', buffering=chunksize) as f:
for fchunk in f:
print(fchunk, end='')
dtime, xx, yy, zz = fchunk.split(",")
date_time_obj = dt.strptime(dtime, '%Y-%m-%d %H:%M:%S.%f')
datetime_array = np.append(datetime_array, date_time_obj)
x_array = np.append(x_array, np.array(xx))
y_array = np.append(y_array, np.array(yy))
z_array = np.append(z_array, np.array(zz))
print(f"---Finished in {time.perf_counter()-starttime:.2f} secs---")
plot_data(datetime_array, z_array, x_array, y_array, output="data_plot_ts_plain_python.png")
data\RCEC7A.csv is of size 619.53 MB
---
---
2021-04-19 10:12:34.641174,0.00939,-0.01165,1.00421
2021-04-19 10:12:34.658445,0.00891,-0.01129,1.00383
2021-04-19 10:12:34.677464,0.0091,-0.01193,1.00395
2021-04-19 10:12:34.694981,0.00905,-0.01166,1.00405
2021-04-19 10:12:34.713283,0.00905,-0.01166,1.00405
2021-04-19 10:12:34.731323,0.0091,-0.01156,1.00422
---Finished in 5.57 secs---
If we simply read the lines as string, we cannot do much data analysis. If we want to analyze the time series available in such data structure, we would like to split our data line by some delimiter (here, it would be a comma). Also in such cases, we cannot use the chunksize (we use 10^6 characters to speed up our run) but instead we need to run it line by line and then split the line into - “date”, “X’”, “Y”, “Z”. The execution of such code will take very long. For the data file I used, there are 12333360 lines. It took several hours to finish the job in the above case. We can achieve significant speed-ups if we perform multithreading. For details on how to implement multithreading, check my post below:
The best approach would be to use Pandas and store the data as dataframe.
Using Pandas
For reading using Pandas, I first created the Numpy array corresponding to each column in the data file and then append to those arrays in steps. Note that one of the column is datetime type and since both Numpy and Pandas supports datetime data types (Pandas datetime is based on Numpy), so we can easily switch between the two.
Still current — with faster options today. pd.read_csv(..., chunksize=N) works identically in pandas 2.x. Two speed-ups worth knowing: pass engine="pyarrow" for a much faster multithreaded CSV parser, and specifying dtype= (as this code does) avoids slow type inference. For a genuinely out-of-core workflow (data larger than RAM), a library like Dask or Polars parallelizes the chunk loop for you.
One performance caveat in the loop. Growing a NumPy array with np.append inside the chunk loop reallocates and copies the whole array on every chunk (O(n²) overall). For large files it’s much faster to collect the chunks in a list and call np.concatenate(list) (or pd.concat) once at the end.
use_pandas = 1
if use_pandas:
chunksize = 10 ** 6
starttime = time.perf_counter()
x_array = np.array([],dtype=np.float64)
y_array = np.array([],dtype=np.float64)
z_array = np.array([],dtype=np.float64)
datetime_array = np.array([],dtype='datetime64')
for df in pd.read_csv(filename, chunksize=chunksize, names=[
'Datetime', "X", "Y", "Z"], dtype={"Datetime": "str", "X": np.float64,"Y": np.float64,"Z": np.float64}):
print(df.head(1))
df["Datetime"] = pd.to_datetime(df["Datetime"])
datetime_array = np.append(datetime_array, df["Datetime"].values)
x_array = np.append(x_array, df['X'].values)
y_array = np.append(y_array, df['Y'].values)
z_array = np.append(z_array, df['Z'].values)
print(datetime_array.shape, x_array.shape, y_array.shape, z_array.shape)
print(f"---Finished in {time.perf_counter()-starttime:.2f} secs---")
plot_data(datetime_array, z_array, x_array, y_array, output="data_plot_ts_pandas.png")
data\RCEC7A.csv is of size 619.53 MB
Datetime X Y Z
0 2021-04-17 00:00:00.005829 0.00824 -0.01095 1.00362
Datetime X Y Z
1000000 2021-04-17 04:43:11.186569 0.00837 -0.0115 1.00344
Datetime X Y Z
2000000 2021-04-17 09:26:22.605798 0.00831 -0.01173 1.00445
Datetime X Y Z
3000000 2021-04-17 14:09:35.332395 0.00873 -0.01218 1.00549
Datetime X Y Z
4000000 2021-04-17 18:52:48.869506 0.00962 -0.01263 1.00514
Datetime X Y Z
5000000 2021-04-17 23:35:59.008793 0.00882 -0.01185 1.00419
Datetime X Y Z
6000000 2021-04-18 04:19:07.557370 0.00869 -0.01218 1.00397
Datetime X Y Z
7000000 2021-04-18 09:02:16.524164 0.00904 -0.01256 1.00471
Datetime X Y Z
8000000 2021-04-18 13:45:21.515661 0.00936 -0.01177 1.00484
Datetime X Y Z
9000000 2021-04-18 18:28:31.620251 0.00946 -0.01205 1.00416
Datetime X Y Z
10000000 2021-04-18 23:11:39.905102 0.00896 -0.01215 1.00442
Datetime X Y Z
11000000 2021-04-19 03:54:48.686318 0.00882 -0.01212 1.0039
Datetime X Y Z
12000000 2021-04-19 08:37:48.242951 0.00922 -0.01121 1.00349
(12333360,) (12333360,) (12333360,) (12333360,)
---Finished in 14.96 secs---
Quick check: What does pd.read_csv(filename, chunksize=10**6, ...) return?
Recap
- Chunk it.
pd.read_csv(..., chunksize=N)yields DataFrames of N rows; loop over them so peak memory ≈ one chunk. - Pandas beats hand-rolled parsing. The pure-Python line-by-line version took hours; the pandas chunk loop finished the 620 MB / 12.3M-row file in ~15 s.
- Type early. Passing
dtype=(andnames=) skips slow inference;engine="pyarrow"speeds up the parse further on pandas 2.x. - Aggregate efficiently. Collect chunks in a list and
concatonce rather thannp.appendin the loop. - Go out-of-core for bigger data. When the result won’t fit in RAM either, reach for Dask or Polars.
Where to go next
- When even chunks aren’t enough — Dask: Using Dask to read a huge global earthquake catalog
pandas.read_csvdocs (chunksize, dtype, engine): pandas.pydata.org/docs/reference/api/pandas.read_csv.html
Complete Codes
Disclaimer of liability
The information provided by the Earth Inversion is made available for educational purposes only.
Whilst we endeavor to keep the information up-to-date and correct. Earth Inversion makes no representations or warranties of any kind, express or implied about the completeness, accuracy, reliability, suitability or availability with respect to the website or the information, products, services or related graphics content on the website for any purpose.
UNDER NO CIRCUMSTANCE SHALL WE HAVE ANY LIABILITY TO YOU FOR ANY LOSS OR DAMAGE OF ANY KIND INCURRED AS A RESULT OF THE USE OF THE SITE OR RELIANCE ON ANY INFORMATION PROVIDED ON THE SITE. ANY RELIANCE YOU PLACED ON SUCH MATERIAL IS THEREFORE STRICTLY AT YOUR OWN RISK.
Leave a comment